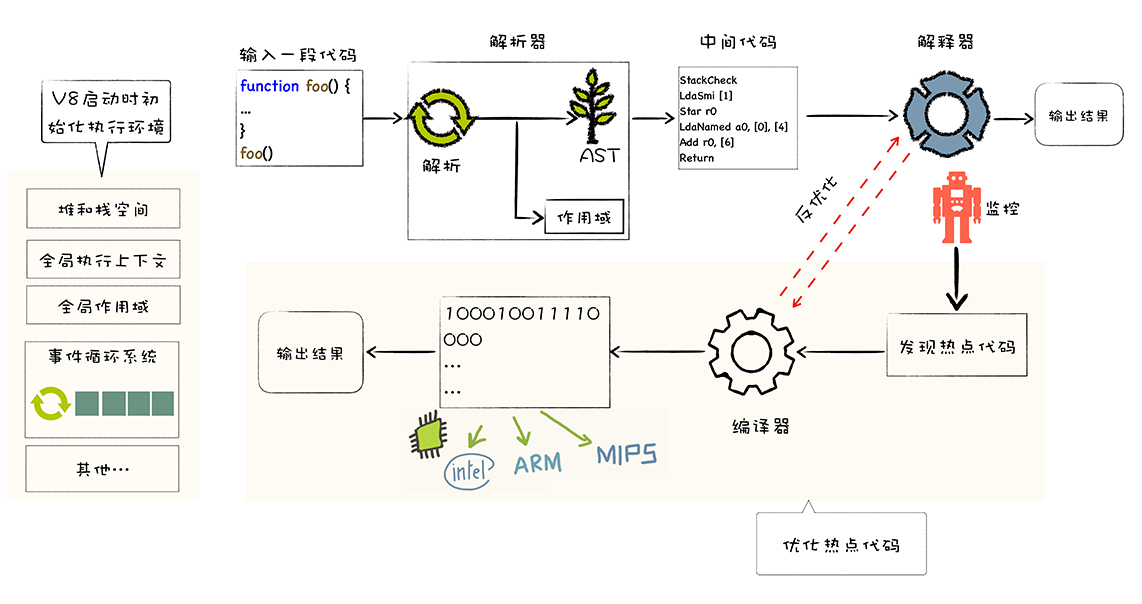
什么是Google V8
- V8 是由 Google 开发的开源 JavaScript 引擎,广泛应用于 Chrome 浏览器和 Node.js,其核心功能是执行 JavaScript 代码。
- 原理:通过即时编译(JIT)和解释执行相结合的方式处理代码。
- 主要流程
- 初始化基础环境。
- 解析源码,生成 AST 和作用域
- 根据 AST 和作用域生成字节码。
- 解释执行字节码。
- 监听热点代码并进行优化,生成二进制代码。
- 反优化生成的二进制代码。
函数即对象
- 在 JavaScript 中,继承是通过对象的原型链实现的。对象的原型属性指向其继承的对象,从而形成一个链式结构。
- 函数在 JavaScript 中是一等公民,可以像其他数据类型一样作为变量、参数和返回值。
对象属性:快属性和慢属性
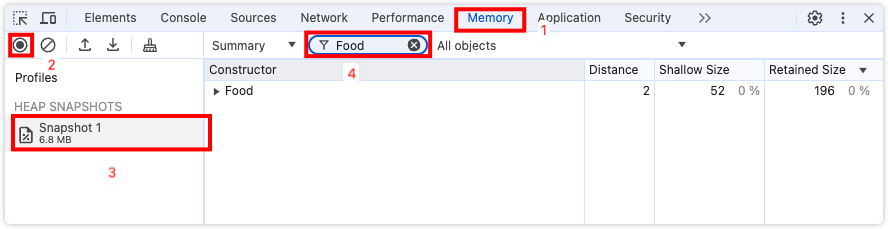
在Chrome中查看内存快照
首先在控制台运行下面的程序
function Food(name, type) {
this.name = name;
this.type = type;
}
var beef = new Food('beef', 'meat');切换到Memory中,点击左侧的小圈圈就可以捕获当前的内存快照。
构造函数创建对象的目的是为了在内存快照中更方便地找到它。在过滤器中输入Food就可以找到Food构造的所有对象。
V8中对象的结构
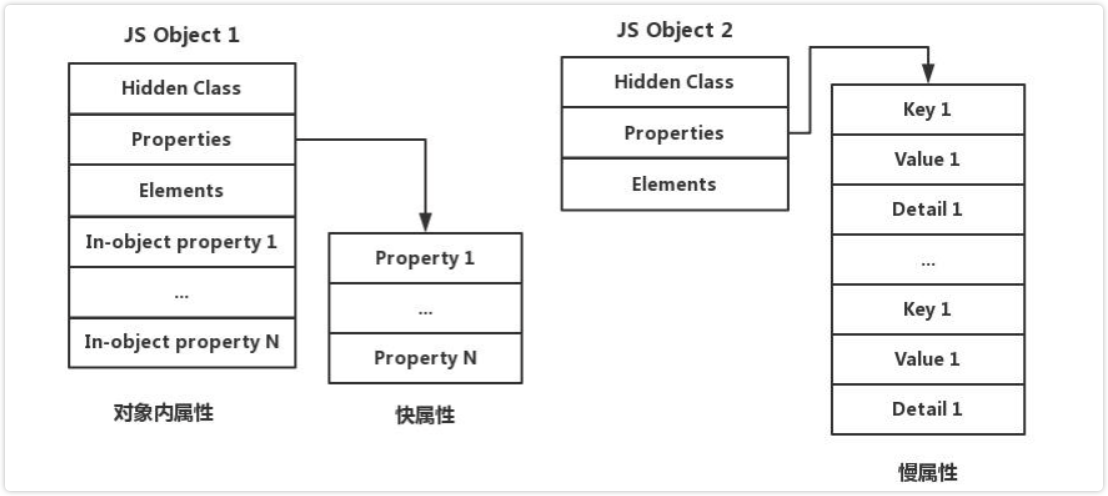
在V8中,对象主要由三个指针构成,分别是隐藏类(Hidden Class),Property还有Element。
其中,隐藏类用于描述对象的结构。Property和Element用于存放对象的属性,它们的主要区别在于键名是否可以被索引。
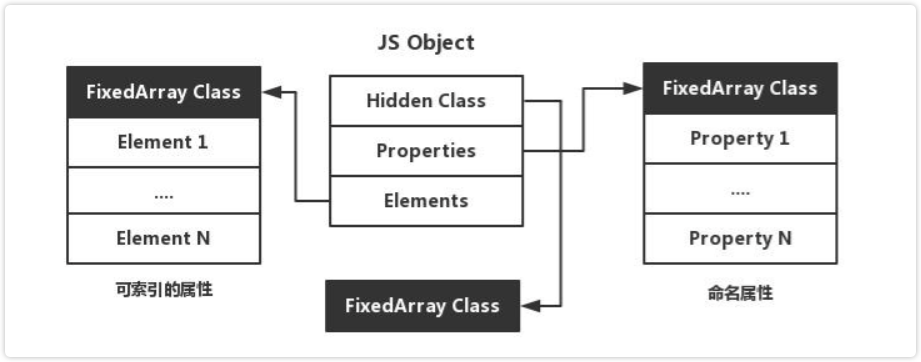
Property 与 Element
// 可索引属性会被存储到 Elements 指针指向的区域
{ 1: "a", 2: "b" }
// 命名属性会被存储到 Properties 指针指向的区域
{ "first": 1, "second": 2 }事实上,这种设计是为了满足 ECMA 规范的要求。按照规范中的描述,可索引属性本身已经有序排列,因此无需通过结构查找。
做个简单的小实验。
var a = { 1: "a", 2: "b", "first": 1, 3: "c", "second": 2 }
var b = { "second": 2, 1: "a", 3: "c", 2: "b", "first": 1 }
console.log(a)
// { 1: "a", 2: "b", 3: "c", first: 1, second: 2 }
console.log(b)
// { 1: "a", 2: "b", 3: "c", second: 2, first: 1 }a和b的区别在于a以一个可索引属性开头,b以一个命名属性开头。在a中,可索引属性升序排列,命名属性先有first后有second。在b中,可索引属性乱序排列,命名属性先有second后有first。
索引属性按照索引值大小升序排列,而命名属性根据创建的顺序升序排列
在同时使用可索引属性和命名属性的情况下,控制台打印的结果中,两种不同属性之间存在明显分隔
无论是可索引属性还是命名属性先声明,在控制台中总是以相同的顺序出现
侧面印证完了,下面来看正面,查看这两种属性的快照
// 实验1 可索引属性和命名属性的存放
function Foo1 () {}
var a = new Foo1()
var b = new Foo1()
a.name = 'aaa'
a.text = 'aaa'
b.name = 'bbb'
b.text = 'bbb'
a[1] = 'aaa'
a[2] = 'aaa'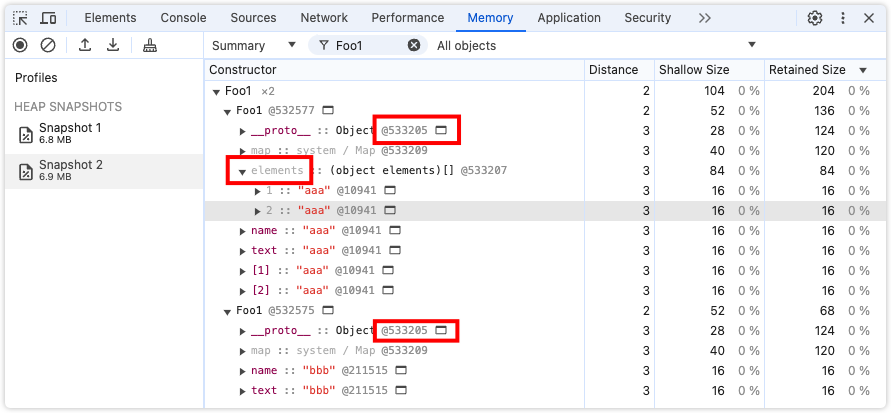
a,b都有命名属性name和text,此外a额外多了两个可索引属性。从快照中可以明显看到,可索引属性是存放在Element中,此外,a和b具有相同的结构。
这两个对象的属性不一样,为什么会有相同的结构呢?先看下面三个问题
为什么要把对象存起来?当然是为了之后用
要用的时候需要做什么?找到这个属性
描述结构为了做什么?方便查找
那么,对于可索引属性来说,它本身已经有序的进行排列了,我们为什么还要多此一举通过它的结构去查找呢。既然不用通过它的结构查找,那么也不需要再去描述它的结构了。这样就不难理解为什么a和b具有相同的结构了,因为它们的结构中只描述了它们都有name和text这样的情况。
当然也有例外,只需在上面的代码中再加入一行。
a[1111] = 'aaa'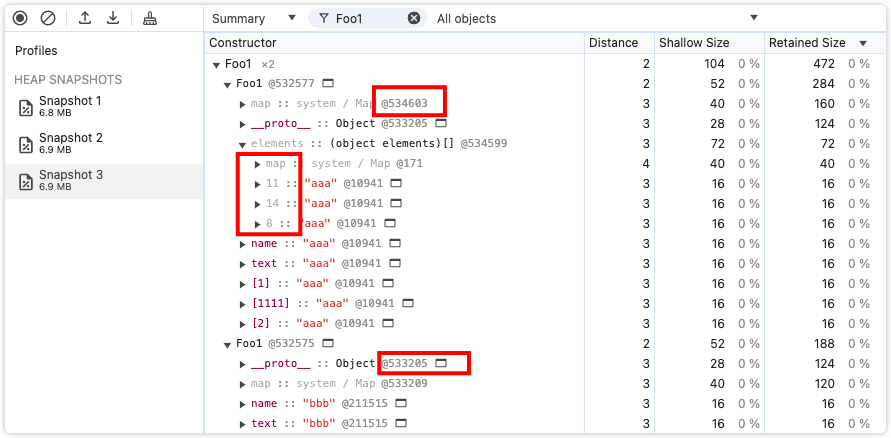
可以看到,此时隐藏类发生了变化,Element 中的数据存放也变得没有规律了。这是因为,当我们添加了 a[1111] 之后,数组会变成稀疏数组。为了节省空间,稀疏数组会转换为哈希存储的方式,而不再是用一个完整的数组描述这块空间的存储。所以,这几个可索引属性也不能再直接通过它的索引值计算得出内存的偏移量。
命名属性的不同存储方式
V8 中命名属性有三种的不同存储方式:对象内属性(in-object)、快属性(fast)和慢属性(slow)。
- 对象内属性保存在对象本身,提供最快的访问速度。
- 快属性比对象内属性多了一次寻址时间。
- 慢属性会将属性的完整结构存储在对象外部,这使得访问速度较慢。(另外两种属性的结构会在隐藏类中描述,隐藏类将在下文说明),
- 速度最慢(在下文或其它相关文章中,慢属性、属性字典、哈希存储说的都是一回事)。
再看下面的例子来说明。
// 实验2 三种不同类型的 Property 存储模式
function Foo2() {}
var a = new Foo2()
var b = new Foo2()
var c = new Foo2()
for (var i = 0; i < 10; i ++) {
a[new Array(i+2).join('a')] = 'aaa'
}
for (var i = 0; i < 12; i ++) {
b[new Array(i+2).join('b')] = 'bbb'
}
for (var i = 0; i < 30; i ++) {
c[new Array(i+2).join('c')] = 'ccc'
}a、b 和 c 分别拥有 10 个,12 个和 30 个属性,Chrome分别会以对象内属性、对象内属性 + 快属性、慢属性三种方式存储。我们分别看一看。
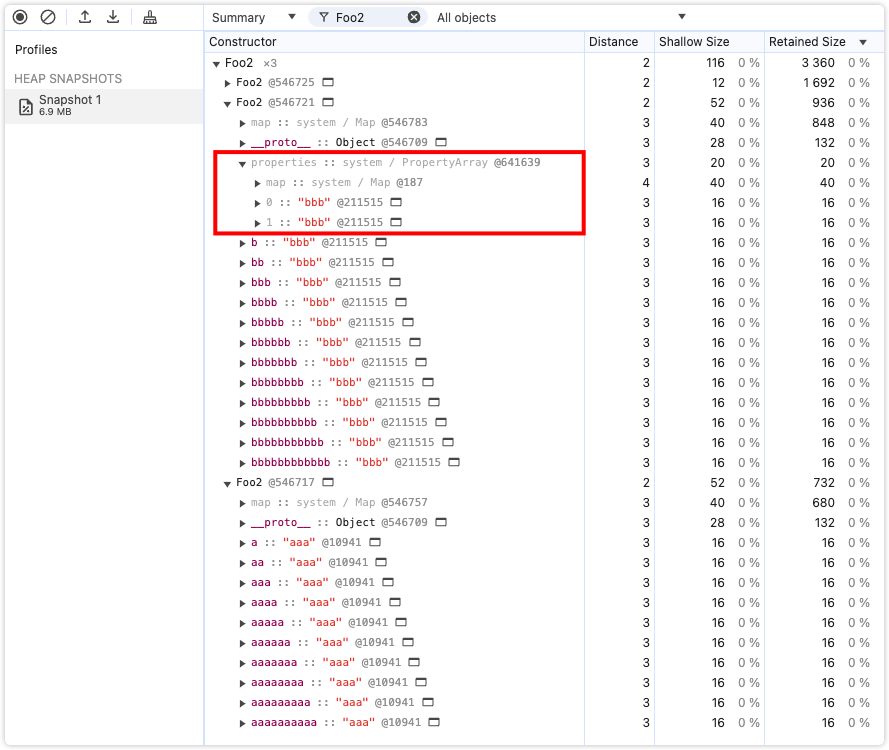
首先我们看一下 a 和 b。从某种程度上说,对象内属性和快属性的工作原理相似。只不过,对象内属性是在对象创建时就固定分配的,空间有限。在我的实验条件下,对象内属性的数量固定为十个,且这十个空间大小相同(可以理解为十个指针)。当对象内属性放满之后,会以快属性的方式,在 properties 下按创建顺序存放。相较于对象内属性,快属性需要额外多一次 properties 的寻址时间,之后便是与对象内属性一致的线性查找。
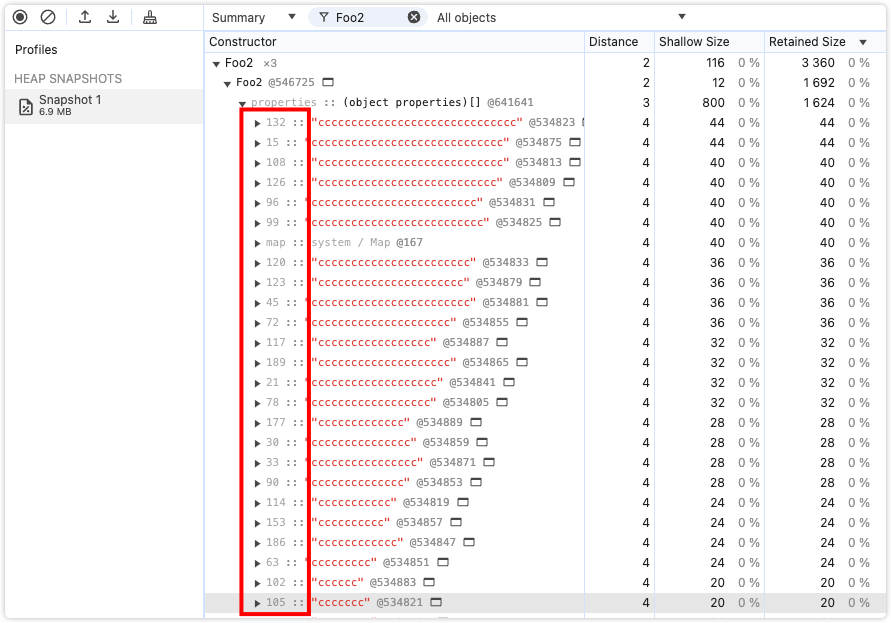
接着我们来看看 c。这个实在是太长了,只截取了一部分。可以看到,和 b (快属性)相比,properties 中的索引变成了毫无规律的数,意味着这个对象已经变成了哈希存取结构了。
为什么要分三种存储方式
最根本原因是为了更快的访问速度
对象内属性和快属性通过线性查找来定位,最多需要 N 次简单位运算,而慢属性则需要通过复杂的哈希算法进行计算,耗时明显增加。此外,哈希表是二维空间,计算出一维坐标后,仍需在另一维度进行线性查找。因此,当属性数量较少时,使用慢属性的效率较低。
当属性太多的时候,这两种方式可能就没有慢属性快了。假设哈希运算的代价为 60 次简单位运算,哈希算法的表现良好。如果只用对象内属性或快属性的方式存,当需要访问第 120 个属性,就需要 120 次简单位运算。而使用慢属性,我们需要一次哈希计算(60 次简单位运算)+ 第二维的线性比较(远小于 60 次,已假设哈希算法表现良好,那属性在哈希表中是均匀分布的)。
隐藏类
Java 这样的静态语言,类型一旦创建变不可更改”可以改为“在 Java 这样的静态语言中,一旦创建了类型,它们就不可更改。
前面也提到,通过哈希表的方式存取属性,需要额外的哈希计算。为了提高对象属性的访问速度,实现对象属性的快速存取,V8 中引入了隐藏类。
隐藏类的另一个优势是显著减少了内存占用。
在 ECMAScript 中,对象属性的 Attribute 被描述为以下结构。 - [[Value]]:属性的值 - [[Writable]]:定义属性是否可写(即是否能被重新分配) - [[Enumerable]]:定义属性是否可枚举 - [[Configurable]]:定义属性是否可配置(删除).
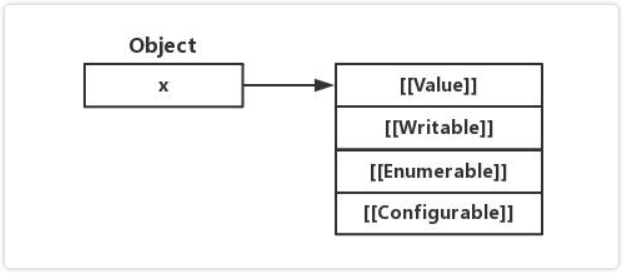
隐藏类的引入,将属性的 Value 与其它 Attribute 分开。一般情况下,对象的 Value 是经常会发生变动的,而 Attribute 是几乎不怎么会变的。那么,我们为什么要重复描述几乎不会改变的 Attribute 呢?显然这是一种内存浪费。
隐藏类的创建机制可以通过以下示例理解
// 实验3 隐藏类的创建
let a = {}
a.name = 'thorn1'
a.text = 'thorn2'通过内存快照,我们也可以看到,Hidden Class 1 和 Hidden Class2 是不同的,并且后者的 back_pointer 指针指向前者。V8 在每次添加属性时创建的新隐藏类会描述对象的所有属性,而不仅仅是新添加的属性。
此外还有一个小小知识点。
// 实验4 隐藏类创建时的优化
let a = {};
a.name = 'thorn1'
let b = { name: 'thorn2' }a 和 b 的区别是”可以更清晰地表达为“a 和 b 的主要区别在于,a 首先创建了一个空对象,然后为其添加了名为 name 的属性,而 b 直接创建了一个包含 name 属性的对象。从内存快照我们可以看到,a 和 b 的隐藏类不一样,back_pointer 也不一样。这主要是因为,在创建 b 的隐藏类时,省略了为空对象单独创建隐藏类的一步。所以,要生成相同的隐藏类,更为准确的描述是 —— 从相同的起点,以相同的顺序,添加结构相同的属性(除 Value 外,属性的 Attribute 一致)。
神奇的 delete 操作
下面我们来看看一下删除操作对于隐藏类的影响。
// 实验5 delete 操作的影响
function Foo5 () {}
var a = new Foo5()
var b = new Foo5()
for (var i = 1; i < 8; i ++) {
a[new Array(i+1).join('a')] = 'aaa'
b[new Array(i+1).join('b')] = 'bbb'
}
delete a.a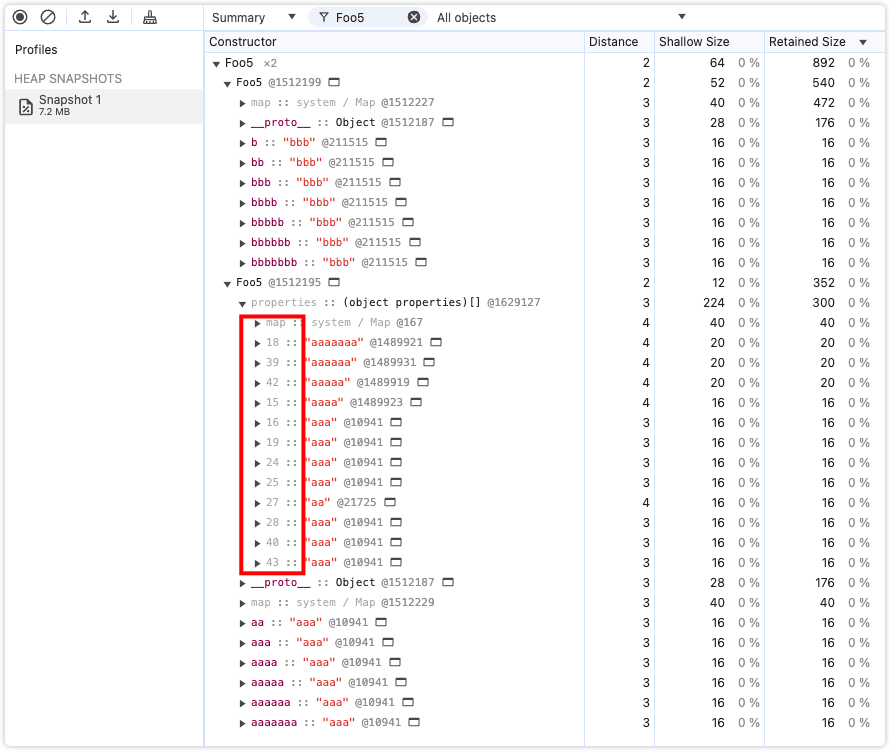
根据之前的试验,a 和 b 的属性最初是通过对象内属性存储的。从快照可以看到,删除了 a.a 后,a 变成了慢属性,退回哈希存储。
但是,如果我们按照添加属性的顺序逆向删除属性,情况会有所不同:对象不会退化为哈希存储。
// 实验6 按添加顺序删除属性
function Foo6 () {}
var a = new Foo6()
var b = new Foo6()
a.name = 'aaa'
a.color= 'aaa'
a.text = 'aaa'
b.name = 'bbb'
b.color = 'bbb'
delete a.text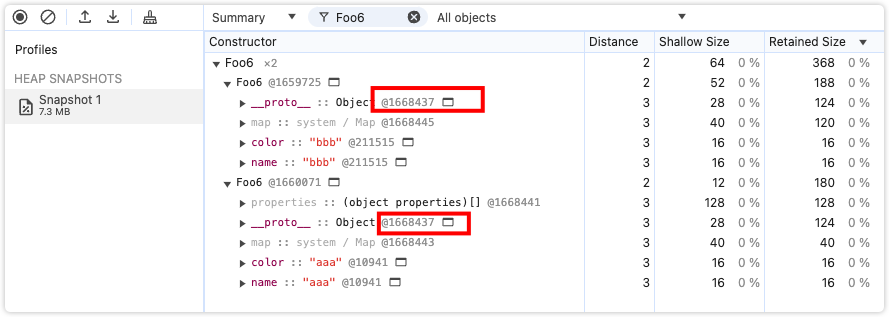
我们给 a 和 b 按相同属性添加相同的属性 name 和 color,再给 a 额外添加一个属性 text,然后删除这个属性。可以发现,此时 a 和 b 的隐藏类相同,a 也没有退回哈希存储。
结论与启示
- 属性分为命名属性和可索引属性,命名属性存放在
Properties中,可索引属性存放在Elements中。 - 命名属性有三种不同的存储方式:对象内属性、快属性和慢属性,前两者通过线性查找进行访问,慢属性通过哈希存储的方式进行访问。
- 总是以相同的顺序初始化对象成员,能充分利用相同的隐藏类,从而提升访问效率。
- 增加或删除可索引属性,不会引起隐藏类的变化,稀疏的可索引属性会退化为哈希存储。
- delete 操作可能会改变对象的结构,导致引擎将对象的存储方式降级为哈希表存储的方式,不利于 V8 的优化,应尽可能避免使用(当沿着属性添加的反方向删除属性时,对象不会退化为哈希存储)。
函数表达式
变量提升:编译阶段将所有变量提升到作用域。变量赋值为undefined,函数赋值函数对象,声明可使用。- 表达式在执行时返回一个值,而语句则不会返回任何值。表达式编译阶段不处理,在执行阶段才完成。函数声明是语句。
- 在 V8 引擎中,遇到函数声明时,它会生成一个函数对象,并将其提升到当前作用域中,这意味着在声明之前也可以调用这个函数。
- 立即函数调用表达式
IIFE,不会污染环境,函数和函数内部的变量都不会被其他部分的代码访问到。
// 函数声明
var n = 1;
function foo(){
n = 100;
console.log(n);
}
console.log(n);
foo()
// 函数表达式
foo() // 报错,此时foo为undefined
var foo = function (){
console.log('foo')
}
// IIFE
var n = 1
!(function foo() {
n = 100
console.log(n)
}())
console.log(n)V8如何实现对象继承
继承是一个对象可以访问另外一个对象中的属性和方法”可以改为“继承指的是一个对象可以访问另一个对象中的属性和方法。
继承机制
原型
- 对象
__proto__
原型链
- 沿着对象的原型一级一级查找属性。
作用域链是沿着函数的作用域一级一级来查找变量。- 继承就是一个对象可以访问另外一个对象中的属性和方法,在JavaScript中,通过原型和原型链的方式实现继承。
__proto__- 对象的原型,
__proto__指向的对象为原型对象,对象可以直接访问其原型对象的方法或属性。 - 这是隐藏属性,并不是标准定义。
- 使用该属性会造成严重的性能问题。
- 对象的原型,
构造函数创建对象 new
- 创建空白对象
- 给新对象设置原型
- 将构造函数的this指向新对象
构造函数实现继承
- 当你将这个函数作为构造函数来创建一个新的对象时,新创建对象的原型对象就指向了该函数的 prototype 属性。
历史
- 虽然 JavaScript 最初并不需要
new关键字来创建新对象,但为了吸引 Java 程序员的注意,JavaScript 引入了这个与 Java 类似的语法结构,尽管这在 JavaScript 的语法中显得不太自然。
jsvar bar = new Foo()- 虽然 JavaScript 最初并不需要
V8如何查找变量
- 全局作用域是在 V8 启动过程中就创建了,且一直保存在内存中不会被销毁的,直至 V8 退 出。 而函数作用域是在执行该函数时创建的,当函数执行结束之后,函数作用域就随之被 销毁掉了。
- 词法作用域指的是查找变量时,依据函数定义时的位置来确定作用域。
//======解析阶段--实现变量提升=======
var name = undefined
var type = undefined
function foo(){
var name = 'foo'
console.log(name)
console.log(type)
}
function bar(){
var name = 'bar'
var type = 'function'
foo()
}
//====执行阶段======== name = '极客时间'
type = 'global'
bar()编译阶段,V8为bar函数创建函数作用域,然后进入了 bar 函数的执行阶段。在 bar 函数中,只是简单地调用 foo 函数,因此 V8 又 开始执行 foo 函数了。同样,在编译 foo 函数的过程中,会创建 foo 函数的作用域,这时候我们就有了三个作用域了,分别是全局作用域、bar 的函数作用域、foo 的函 数作用域。
查找顺序都是按照当前函数作用域–> 全局作用域这个路径来的。
V8如何实现类型转换
在执行加法过程中,V8 会先通过 ToPrimitive 函数,将对象转换为字符串或数字等基本类型,在转换过程中,ToPrimitive 会先调用对象的 valueOf 方法,如果没有 valueOf 方法,则调用 toString 方法,如果 vauleOf 和 toString 两个方 法都不返回基本类型值,便会触发一个 TypeError 的错误。
补充:V8执行代码流程图